A
data warehouse is a repository
(collection of resources that can be accessed to retrieve information) of an
organization's electronically stored data, designed to facilitate reporting and
analysis. In simple form data warehouse is a collection of large amount of data.
§
A DWH is a historical database because the database
contains many years of historical business data for Decision making purpose.
§
A DWH system is designed to read the business data for
business analysis processing but not for Transactional processing. Hence it is
called as a Read only database.
A
DWH is designed to take the decision. Hence it is also known as DSS (Decision Supportive System).
1.
The fathers of
DWH are W.H. Inmon & Ralph Kimball.
W.H.Inmon defined the DWH as
Time
Variant, Non Volatile, Integrated and Subject Oriented.
I.
Time Variant:
In order to discover trends in business, analysts need large amounts of data.
This is very much in contrast to online
transaction processing (OLTP) systems, where performance requirements
demand that historical data be moved to an archive. A data warehouse's focus on
change over time is what is meant by the term time variant.
A business user can
analyze the business data in the warehouse to the different time periods like
Year, Quarter, Month, and Weeks etc.
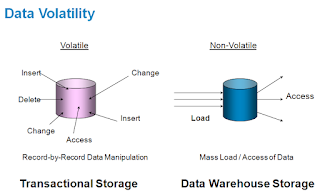
II.
Non Volatile:
Nonvolatile means that, once entered into the warehouse, data should not
change. This is logical because the purpose of a warehouse is to enable you to
analyze what has occurred. The data that is present in the DWH is Static.
III.
Integrated:
Data warehouses must put data from disparate sources into a consistent format.
They must resolve such problems as naming conflicts and inconsistencies among
units of measure. When they achieve this, they are said to be integrated.
IV.
Subject Oriented: Data warehouses are designed to help you analyze data. For example, to
learn more about your company's sales data, you can build a warehouse that
concentrates on sales. Using this warehouse, you can answer questions like
"Who was our best customer for this item last year?" This ability to
define a data warehouse by subject matter, sales in this case makes the data
warehouse subject oriented.


1.
Types of DWH
systems: There are mainly 2 types of DWH
systems.
I.
EDW (Enterprise Data Warehouse): It contains the historical business data at the enterprise
level to support the business needs of top management in the organization.
- Contains data drawn from multiple operational systems.
- Supports time- series and trend analysis across different business areas.
- Can be used to populate data marts
- Can be used for everyday and strategic decision making.
II.
Data Marts:
A data mart is a subset of an organizational data store, usually oriented to a
specific purpose or major data subject, which may be distributed to support
business needs.
- Subset of enterprise data warehouse.
- Organized around a single business process.
- May or may not contain aggregates.

1.
Staging Area:
v A storage area and set of process that clean,
transform, combine, removing duplicate, archive and prepare source data for use
in data warehouse.
v It accepts data from different sources.
v The structure is closer to the Operational Systems
rather than the DW.
v Data arriving at different point of time is merged and
then loaded into the DW.
v Usually does not maintain history; only a temporary
area.
2.
Types of DWH approach:-
I.
Top – Down approach: According to W.H.Inmon, we need to develop the enterprise DWH system
and then from the EDW develop subject oriented databases called Datamarts
according to the business needs.
II.
Bottom – Up approach: According to Ralph Kimball, 1st develop
the datamarts according to business needs and then integrate all datamarts into
EDW.
3.
Types of Data Marts:
I.
Dependent DM:
The DM developed in Top – Down approach is known as Dependent DM. Because 1st
we will load data into EDW and then into DM.
II.
Independent DM:
The DM developed in Bottom – Up approach is known as Independent DM. Because 1st
we will load data into DM and then into EDW.
·
Please find below
the example for Dependent Datamart.

1.
Real Time DWH:
Traditionally data warehouses do not contain today's data. They are usually
loaded with data from operational systems at most weekly or in some cases
nightly, but are in any case a window on the past.
As today's
decisions in the business world become more real-time, the systems that support
those decisions need to keep up. It is only natural that Data Warehouse,
Business Intelligence, Decision Support, and OLAP systems quickly begin to incorporate real-time data. Data
warehouses and business intelligence applications are designed to answer
exactly the types of questions that users would like to pose against real-time
data. Ad-hoc reporting is made easy
using today's advanced OLAP tools.
2.
Data Acquisition:
§ Data
Acquisition means Extraction, Transformation & Loading.
Here we will extract data from different sources like COBOL, ERP, Operational etc and bring
into our Staging Area. Staging Area is a
temporary storage area. From Staging Area we will load data into DWH or DM’s.
§ Data acquisition process is defined with Data
extraction, Data transformation and Data loading.
I.
Data Extraction: It is a process of reading the data from different sources like
Operational sources, ERP systems, COBOL files, Flat files etc.
II.
Data Transformation: It is a process of transforming data from one format
to required business format. In Data transformation we are having 4 types.
i.
Data Merging:
It is a process of integrating the data from similar sources with the similar
structure and data type. Ex: Join, Union
etc.
ii.
Data Cleansing:
It is a process of identifying and changing the inconsistencies and in
accuracies. Ex: Initcap, Lower, Upper,
NVL etc.
iii.
Data Scrubbing:
It is a process of deriving new definitions from existing source definitions.
Ex: In target table we will add a new column ‘TAX’, which will be calculated
based on the column ‘SAL’ coming from the source.
iv.
Data Aggregation: It is a process of where multiple detail values are summarized into a
single summary values typically numeric like Sum, Average, Min, Max etc.
3.
Star Schema:
§ A star schema is a logical database design which
contains a centrally located fact table
surrounded by at least one or more dimension
tables.
§ A Fact table
contains composite keys (More than one key) where each candidate
key is a foreign key to the dimension
table.
§ The facts that the data warehouse helps analyze are
classified along different dimensions:
·
The fact table holds the main data. It includes a large amount of aggregated
data, such as price and units sold. There may be multiple fact tables in a
star schema.
·
Dimension tables, which are usually smaller than fact tables, include the attributes that describe the facts. Often this is a separate table for each
dimension. Dimension tables can be joined to the fact table(s) as needed.
·
Dimension tables have a simple primary key, while fact
tables have a set of foreign keys which make up a compound primary key
consisting of a combination of relevant dimension keys.
§ Example: Fact.Sales
is the fact table and there are three dimension tables Dim.Date, Dim.Store and Dim.Product. Each dimension table has a
primary key on its PK column, relating to one of the columns (viewed as rows in
the example schema) of the Fact.Sales table's three-column (compound) primary
key (Date_FK, Store_FK, Product_FK). The non-primary key [Units Sold] column of
the fact table in this example represents a measure or metric that can be used
in calculations and analysis. The non-primary key columns of the dimension
tables represent additional attributes of the dimensions (such as the Year of
the Dim.Date dimension).

1.
Snow Flake Schema:
§ In a Star schema database design, if the dimension table is split into a one or more dimension tables
which results in Normalization. Since the database design looks like a snow
flake. Hence it is known as Snow flake schema.
§ Generally
these types of schema designs are not recommended for the warehouse
implementations because dimension tables results in Normalization and decrease
the performances.
§ The snowflake schema is similar to the star schema.
However, in the snowflake schema, dimensions are normalized into multiple
related tables, whereas the star schema's dimensions are denormalized with each
dimension represented by a single table.



·
The advantages
and disadvantages of snow flake schema are given below.
1.
Galaxy Schema:
Sophisticated
applications may require multiple fact tables
to share dimension tables. This kind of schema can be viewed as a
collection of stars, and therefore it's called a Galaxy Schema or a Fact Constellation. As we see in the two star
schemas as above, the two fact tables, sales table and purchase table are now
sharing both the 'product' and 'time' dimension tables. Therefore we decide to
choose Galaxy Schema as the model for our data warehouse, which is displayed as
follow:
Before
applying Galaxy schema:

After
applying Galaxy schema:

1.
Fact Tables:
§ A fact table
contains composite keys (More than one key) where each candidate key is a foreign key to the dimension table.
§ A fact table
contains facts. In DWH, facts are
generally numeric.
§ A measure is a
numeric attribute of a fact, representing the performance or behavior of
the business relative to dimensions.
§ A fact table
contains the fact information at the lowest level granularity.
§ The level at which fact information stores in a fact
table is called as Fact Granularity or
Grain of fact.
§ A fact table
can contain fact information either in 1NF or 2NF or 3NF. (NF: Normalization
Form).
§ To provide the meaningful business context to the
facts design the dimension tables with a de-normalized business information.
Types of Fact Tables:
I.
Additive Fact table:
§ A fact which can be summed up for any of the dimensions available in the fact table is
called as Additive fact.
Example: Sales
Amount by Store by Product in a given day is an additive fact as it can be summed
up across all STORE, PRODUCT and TIME dimensions. We can sum the Sales for a
week to get the Total Sales Amount for that week.
II.
Semi Additive Fact table:
§ A fact which can
be summed up for few dimensions but not
for all the dimensions present in the fact table.
Example: Current Balance for
an Account is the Semi-Additive fact as it can be summed up for all Accounts to
find out the Total current balance of the Bank. It won’t make sense to sum up
the Current Balance for an Account in a given month (Time).
III.
Non
Additive Fact table:
§ A fact which cannot
be summed up for any of the dimensions available in the fact table.
Example: AVERAGE.
IV.
Fact
less Fact Table:
§ A fact which
contains only Keys but not measures.
Types of Facts:
I.
Accumulative Fact Table:
§ Generally these fact tables describe what has happened over the period of time. A cumulative fact table contains Additive or Semi additive facts.
Ex: Transactional fact table, Orders fact table.
II.
Snap shot Fact Table:
§ This type of fact table describes the status of things at a particular instant of the time.
Dimension Tables:
·
The dimension tables contain attributes (or
fields) used to constrain and group data when performing data warehousing
queries.
·
In a data
warehouse, a dimension is a data element that categorizes each item in a data
set into non-overlapping regions.
·
For example,
"Customer", "Date", and "Product" are all
dimensions that could be applied meaningfully to a sales receipt.
Types of Dimensions Tables:
I.
Conformed Dimension: The dimension that is shared
across multiple fact tables. At the most basic level, conformed dimensions
mean the exact same thing with every possible fact table to which they are
joined. The date dimension table connected to the sales facts is identical to
the date dimension connected to the inventory facts. Ex: Time Dimension,
Geographical Dimension.
II.
Junk Dimension: Junk dimension is just a dimension that stores
unwanted attributes. A junk dimension
is a convenient grouping of typically low-cardinality flags and indicators. By
creating an abstract dimension, these flags and indicators are removed from the
fact table while placing them into a useful dimensional framework. Ex:
|
Source
|
Junk Dimension
|
||||
|
FLAG_1
|
Yes/No
|
Key_ID
|
Flag_1
|
Flag_2
|
|
|
FLAG_2
|
True/False
|
1
|
Yes
|
TRUE
|
|
|
2
|
Yes
|
FALSE
|
|||
|
3
|
No
|
TRUE
|
|||
|
4
|
No
|
FALSE
|
|||
III.
Degenerated Dimension: In a data
warehouse, a degenerate dimension is a dimension which is derived from the fact
table and doesn't have its own dimension table. The decision to use
degenerate dimensions is often based on the desire to provide a direct
reference back to a transactional system without the overhead of maintaining a
separate dimension table. A dimension key, such as a transaction number,
invoice number, ticket number, or bill-of-lading number, that has no attributes
and hence does not join to an actual dimension table. Degenerate dimensions are
very common when the grain of a fact table represents a single transaction item
or line item because the degenerate dimension represents the unique identifier
of the parent.
IV.
Slowly Changing Dimension: Slowly Changing Dimensions (SCDs) are dimensions
that have data that changes slowly, rather than changing on a time-based,
regular schedule. It’s further classified into 3 types.
·
SCD Type 1: This
type of dimension table maintains the
latest or current data.
·
SCD Type 2: This
type of dimension table maintains complete
history.
·
SCD Type 3: This
type of dimension table maintains partial
history.
V.
Monster Dimension: The dimension that contains
> 100 million records.
Example: Customer
Dimension.
VI.
Casual Dimension: In most data warehouses, you
build a fact table record when something happens.
The below are the
differences between systems.
OLTP OLAP
1. It is
dynamic. 1. It is static [unchanged].
2. It
follows normalization. 2. It follows denormalization.
3. It
contains current data. 3. It contains
historical data.
4. It is
designed to support transactional 4.
It is designed to support decision making process. process.
5. It
contains detailed data. 5. It contains summarized
information.
ODS
DWH
1. It is
designed to support operational
1. It is designed to support decision making process. process.
Similarities:-
2.
Integrated database. 2. Integrated database.
3.
Enterprise data. 3. Enterprise data.
4. Subject
oriented database. 4. Subject oriented database.
Differences:-
5. Contains
current information. 5. Contains historical information.
6. Data is
volatile. 6. Data is non-volatile.
7. Contains
detail information. 7. Contains summary information.
ODS OLTP
1. Subject
oriented database. 1.
Application oriented database.
OLTP DWH
1. Data is
volatile. 1. Data is non-volatile.
2. It
contains current data. 2. It contains historical data.
3. It is
application oriented database. 3. It
is subject oriented database.
4. It is not
flexible. 4. It is flexible.
5. It stored
all data. 5. It stores relevant data.
OLTP DSS
1. It is
designed to support operational
1. It is designed to support decision making process. Process.
2. Data is
volatile. 2. Data is non-volatile.
3. Data is
in inconsistency form.
3. It is in consistent form.
4. It stores
recent data for approximately 4. It
stores One year data.
4 to 6
months data.
5. It
follows normalized schema. 5. It follows star schema.
DWH DM
1. It is
about entire organization. 1. It is about individual department in the
organization.
2. It is
created on RDBMS. 2. It is created on RDBMS
& MDDB.
3. It
follows integrated schema design. 3. It follows star schema design.
4. It is
integrated database. 4. Subject oriented
databases.


You are amazing! Very informative and easy to understand.
ReplyDelete